Introduction to Deep Learning
Deep learning vs. Machine learning
Machine learning
Machine learning is a subfield of artificial intelligence that focuses on teaching computers how to learn without being specifically programmed for certain tasks. The idea is to create algorithms that learn from data and make predictions on data. Machine learning can be split into three categories:
- Supervised learning: the computer is given training data and the desired output from that data (e.g. category labels) and it has to learn from the training data in order to make meaningful predictions based on new data.
- Unsupervised learning: the computer is given data only and it has to find meaningful structure or groups in the data by itself with no supervision.
- Reinforcement learning: the computer is interacting with the environment and learning via feedback which behaviors generate rewards.
We will be using supervised learning for the task of classification.
Deep learning
Deep learning is a subset of machine learning methods that use artificial neural networks. It is somewhat inspired by the structure of the neurons of the brain. The "deep" in deep learning refers to the multiple hidden layers of the neural networks. Deep learning has had great success with several domains, such as images, text, speech, and video. There are many different types of neural networks. We will focus on the following two:
- Multi-layer Perceptron (Fully connected network)
- Convolutional Neural Network
Why use deep learning?
Deep learning is most appropriate when there are very complex patterns in the data you want classified (and also lots of data).
Perceptrons
To begin to understand neural networks we should understand what a perceptron is. A perceptron is a basic artificial neuron. It takes in multiple binary inputs and produces a single binary output. The inputs are given weights and the output is determined by whether the sum of the input weights are over or under a certain threshold. Essentially, it is a device that makes decisions by weighing all the evidence.
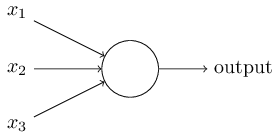
Perceptrons can be combined together in layers to create a network. Each perceptron (node) in a layer weighs the evidence of the perceptrons of the previous layer. The first layer weighs the input evidence and makes a decision. The second layer weighs the results of the first layer and makes a more complex/abstract decision, and so on, until the final layer, where a final decision is made.
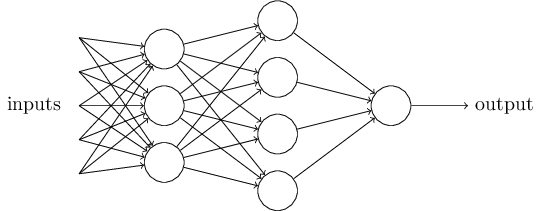
The weights of the inputs of these networks are learned through learning algorithms that minimize the errors in the final output. Nowadays, perceptrons are not really used because their inputs and outputs are binary. Instead sigmoid neurons or other more powerful activation functions like ReLU are often used. Sigmoid neurons operate very similar to perceptrons, however they can take input values between 0 and 1 as well as give output values that are between 0 and 1. More on this later.
Structure of a Neural Network
A neural network is a highly structured network that has multiple layers. The first layer is called the input layer and the final layer is called the output layer. Every layer in between is referred to as a hidden layer. Each layer is made up of multiple nodes (e.g. the perceptrons/sigmoid neurons from above). Each node of the hidden and output layers has its own classifier and the results of the classifiers are passed forward to the next layer. These multiple layer networks are often called Multi-layer Perceptrons (although they are typically not actually using perceptrons). Neural networks like these, where the output from one layer is the input for another, are called feedforward or forward propagation networks. There are neural networks, called Recurrent Networks, where feedback loops can be used and information is not only fed forward, however these are less popular and will not be used in this tutorial.
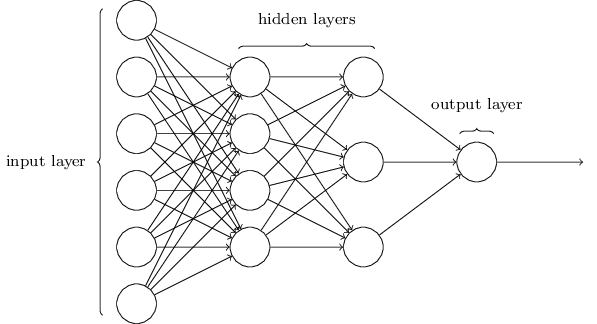
Input layer
The number of nodes in the input layer is determined by the number of inputs. For example, say we are doing image classification and the input is a 28 by 28 pixel image. The model would have one input node for each pixel. There are 784 (28x28=784) pixels in the image, so there would be 784 input nodes.
Output layer
The number of nodes in the output layer is determined by the number of categories the inputs are being classified into. If it is a binary classification (2 options), the output layer has 1 node (the options are 0 or 1). If there are 5 possible categories, there are 5 nodes.
Hidden layers
The number of nodes in the hidden layers is chosen by the user. This is unfortunately not determined by anything in particular and is one of the parameters that will need to be optimized. It is best to test different amounts of nodes and see how it affects the outcome.
Training a neural network
In order to train a neural network we use a process called back propagation. It is essentially a way of progressively correcting mistakes as soon as they are detected. Each layer of a network has a set of weights that determines the output of that layer for a given set of inputs. In the beginning those weights are randomly assigned. The network is activated and values are propagated forward through the network. Since we know the actual value of what the output should be we can calculate the error in prediction. We then propagate the error backwards through the network and use a gradient descent algorithm to adjust the weights to minimize the error. This process repeats until the error reaches below a certain threshold.
One-hot encoding
Deep learning requires that the categories used in classification be represented by
one-hot encoding. This is done by representing the category of each input as a vector
the length of the number of categories. The vector is filled with 0's except for the
specific category belonging to that input. For example, imagine I have 10 samples and
the first 5 are from female subjects and the second 5 are from male subjects. I might
normally represent this data in a list of strings: labels = [female, female, female,
female, female, male, male, male, male, male] or better yet a list of integers
where 1 = male and 2 = female: labels = [2, 2, 2, 2, 2, 1, 1, 1, 1, 1]
One-hot encoding would change the represention from 1 and 2 to male = [1, 0]
and female = [0, 1] so that the ten subjects would be represented as:
labels = [[0, 1], [0, 1], [0, 1], [0, 1], [0, 1], [1, 0], [1, 0], [1, 0], [1, 0]].
This can be further reduced to just labels = [0,0,0,0,0,1,1,1,1,1].
Another example: If you had five categories: [A, B, C, D, E], a sample belonging to
category 'C' would be represented by [0, 0, 1, 0, 0], a sample belonging to category
A would be represented by [1, 0, 0, 0, 0].
Please continue on to the next section 2. Intro to Keras. Keras is the python library we will be using to create neural networks.
Figures are from this very helpful resource: neuralnetworksanddeeplearning.com