Evaluating Neural Networks
A main goal of machine learning is to create models that generalize, meaning that they perform well on data that has not been seen before. To test the generalization power of a model you typically need to split your available data into three separate datasets: a training set, a validation set, and a testing set. You then train the model on the training data and evaluate its performance with the validation data. Once the model is sufficiently accurate, you test it a final time on the testing data. It is best to test it on a completely new third (testing) dataset to avoid overfitting to the validation data. When you are training the model, you are making descisions based on how accurately it classifies (or predicts etc.) the validation data. This inadvertently teaches the model what the validation data looks like and it is possible to overfit and overoptimize it for the validation data even if the model never sees the data in training.
First, some terms:
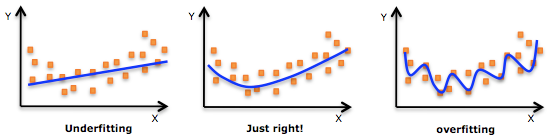
Underfitting
Underfitting is when the model does not fit the training data very well and therefore cannot generalized to the validation or testing data. The model has poor predictive abilities and its accuracy is low.
Overfitting
Overfitting is when the model fits the training or validation data too well. It becomes too specialized for that data and cannot generalize to new data. It has very high accuracy for the training data, but performs poorly when evaluated with new data.
Splitting the data:
There are a couple of ways to split the data to help avoid these problems:
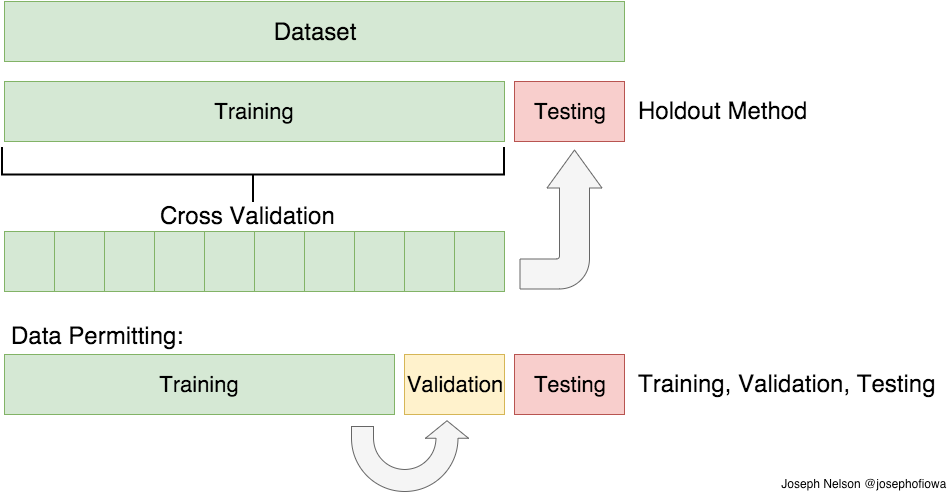
Hold out validation
Hold out validation is simply splitting the data into multiple groups and 'holding' one or more groups (testing/validation) 'out' from training. This works ok, but sometime the split is not as random as we would like.
Manually
This is example, semi-pseudocode. You would also need to do the same with the labels.
#set the number of samples you want to use as validation data
num_validation_samples = 10000
#set the number of samples you want to use as testing data
num_test_samples = 5000
#shuffle the data
np.random.shuffle(data)
#extract the testing data (select the first 5000 samples)
test_data = data[:num_test_samples]
#extract the validation data (select the sample entries between 5000 and 15000)
validation_data = data[num_test_samples:num_validation_samples+num_test_samples]
#extract the training data (select the sample entries from 15000 to the end)
training_data = data[num_validation_samples+num_test_samples:]
# At this point you can tune your model,
# retrain it, evaluate it, tune it again...
model = get_model()
model.train(training_data)
validation_score = model.evaluate(validation_data)
# Once model is sufficiently tuned, evaluate it on the test data
model = get_model()
model.train(np.concatenate([training_data,
validation_data]))
test_score = model.evaluate(test_data)
Using sklearn
This is probably the easiest option. sklearn has a built in function for splitting up datasets and the labels as well, however it will only split the data into two sets (a training and testing set). You can simply use the function twice. sklearn documentation on the function.
from sklearn.model_selection import train_test_split
#set up the data
X = data
Y = data_labels
#choose what proportion of the data you want to be used for training and validation
test_size = .8
#split the data into 80% training (train + val) and 20% testing
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size)
test_size = .75
#you can use the function again to split up the training/validation data
X_train, X_val, y_train, y_val = train_test_split(X_train, Y_train, test_size=test_size)
#this splits the data:
- 20% test
- 60% train
- 20% validation
Cross Validation
Sometimes there is just not enough data to split into three useful groups. In this case, cross validation can be used. Cross validation is also useful for ensuring the data split is representative and not biased (by training on multiple subsets of data).
Cross validation consists of splitting the data into subsets of data. You then train on all but one of those subsets and test on the subset that was held out. This is then repeated, but a different subset is held out each time, until each subset has been the 'test' subset once. The final accuracy is the average accuracy of each training/testing round.
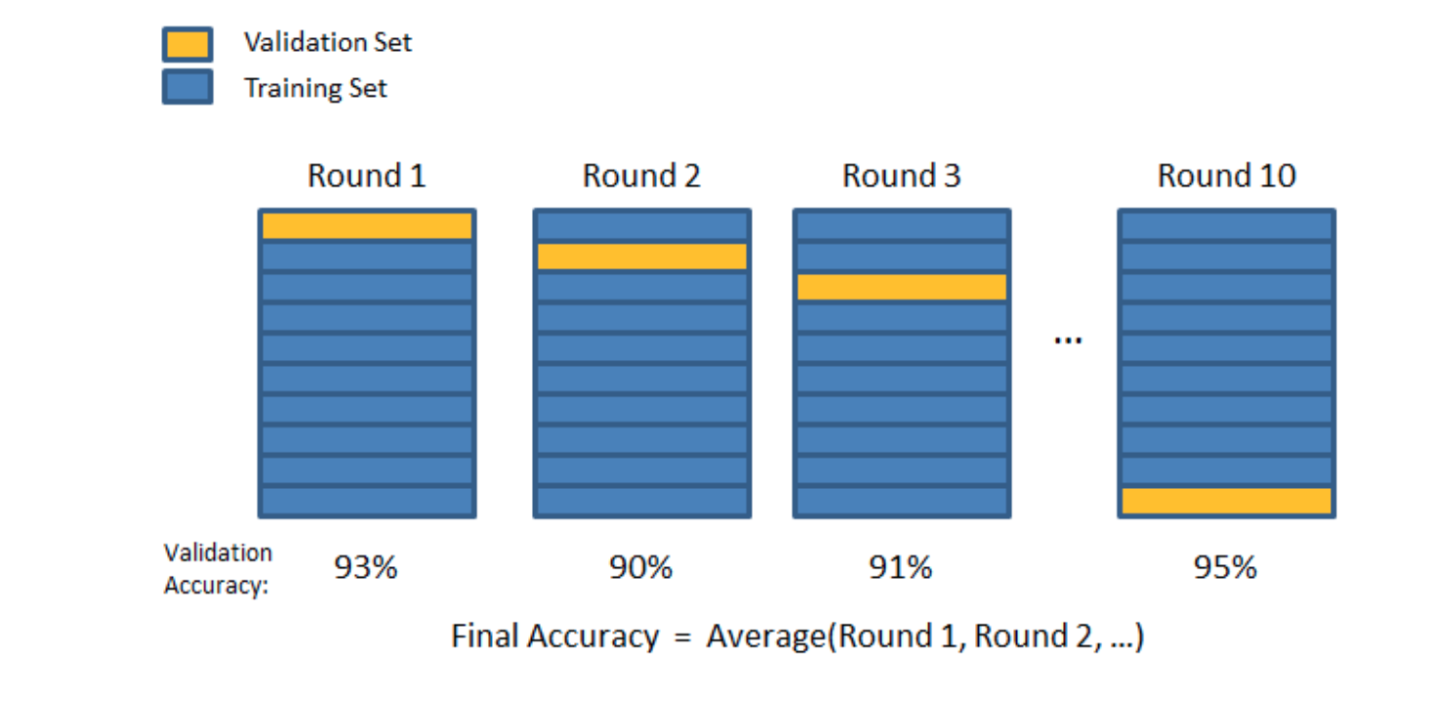
There are several types of cross validation. We will cover K-folds cross validation, Iterated K-folds cross validation, and Leave One Out cross validation.
K-folds cross validation
K-folds cross validation consists of splitting the data into k subsets (folds) of equal size. The model is trained on k-1 subsets and tested on the subset left out. This is repeated until all subsets are the testing subset at least once. The final accuracy of the model is the avearge accuracy of each training/testing round.
sklearn has a function that makes this easy to do. sklearn documentation.
from sklearn.model_selection import KFold
X = data
y = labels
#choose how many folds/subsets you want
kf = KFold(n_splits=10)
#iterate through the splits and save the results
validation_scores = []
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = get_model()
model.train(X_train, y_train)
validation_score = model.evaluate(X_test, y_test)
validation_scores.append(validation_score)
#get average score
validation_score = np.average(validation_scores)
#test on final test data if it was held out
model = get_model()
model.train(data)
test_score = model.evaluate(test_data, test_labels)
Iterated K-folds cross validation
Iterated K-folds cross validation is useful when you have relatively little data available and you need to evaluate your model as precisely as possible. It consists of applying K-fold cross validation multiple times and shuffling the data every time before splitting the data into k subsets. The final score is the average of the scores of each k-fold cross validation. This can be computationally expensive as you train and test n x k times, where n is the number of iterations.
This can be done with an sklearn function. sklearn documentation
from sklearn.model_selection import RepeatedKFold
X = data
y = labels
#establish the function, choos the number of folds and number of repeats
rkf = RepeatedKFold(n_splits=2, n_repeats=2)
#iterate though the folds and repeats
validation_scores = []
for train_index, test_index in rkf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = get_model()
model.train(X_train, y_train)
validation_score = model.evaluate(X_test, y_test)
validation_scores.append(validation_score)
#get average score
validation_score = np.average(validation_scores)
#test on final test data if it was held out
model = get_model()
model.train(data)
test_score = model.evaluate(test_data, test_labels)
Leave One Out (LOO) cross validation
Another option when you have relatively little data, is to use LOO cross validation. The is essentially K-fold cross validation when k is equal to the number of samples in the dataset. You train on all but one sample and test just the sample that was left out. This is repeated until every sample has been the test sample. The final accuracy is the average accuracy across all samples. This is computationally expensive, but useful for small datasets.
sklearn has a function for this as well. sklearn documentation
from sklearn.model_selection import LeaveOneOut
X = data
y = labels
# establish the function
loo = LeaveOneOut()
#iterate through the samples
validation_scores = []
for train_index, test_index in loo.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = get_model()
model.train(X_train, y_train)
validation_score = model.evaluate(X_test, y_test)
validation_scores.append(validation_score)
#get average score
validation_score = np.average(validation_scores)
#test on final test data if it was held out
model = get_model()
model.train(data)
test_score = model.evaluate(test_data, test_labels)
Useful Resources:
source of images: https://towardsdatascience.com/train-test-split-and-cross-validation-in-python-80b61beca4b6
Please continue on to Data Preprocessing.